Evaluation Workflow Overview
Tell Us About Your Product
Provide details about your product so our models can create tailored testing content.
1. Tell Us About Your Product
If you’re new to Galtea, start by creating an account and registering your first product in the dashboard: Go to the dashboard. Follow the Onboarding checklist on the product page (this is the guided setup shown inside your product). It will prompt you for product details and help you generate an API key. The product details you provide there are used to tailor generated tests and evaluations.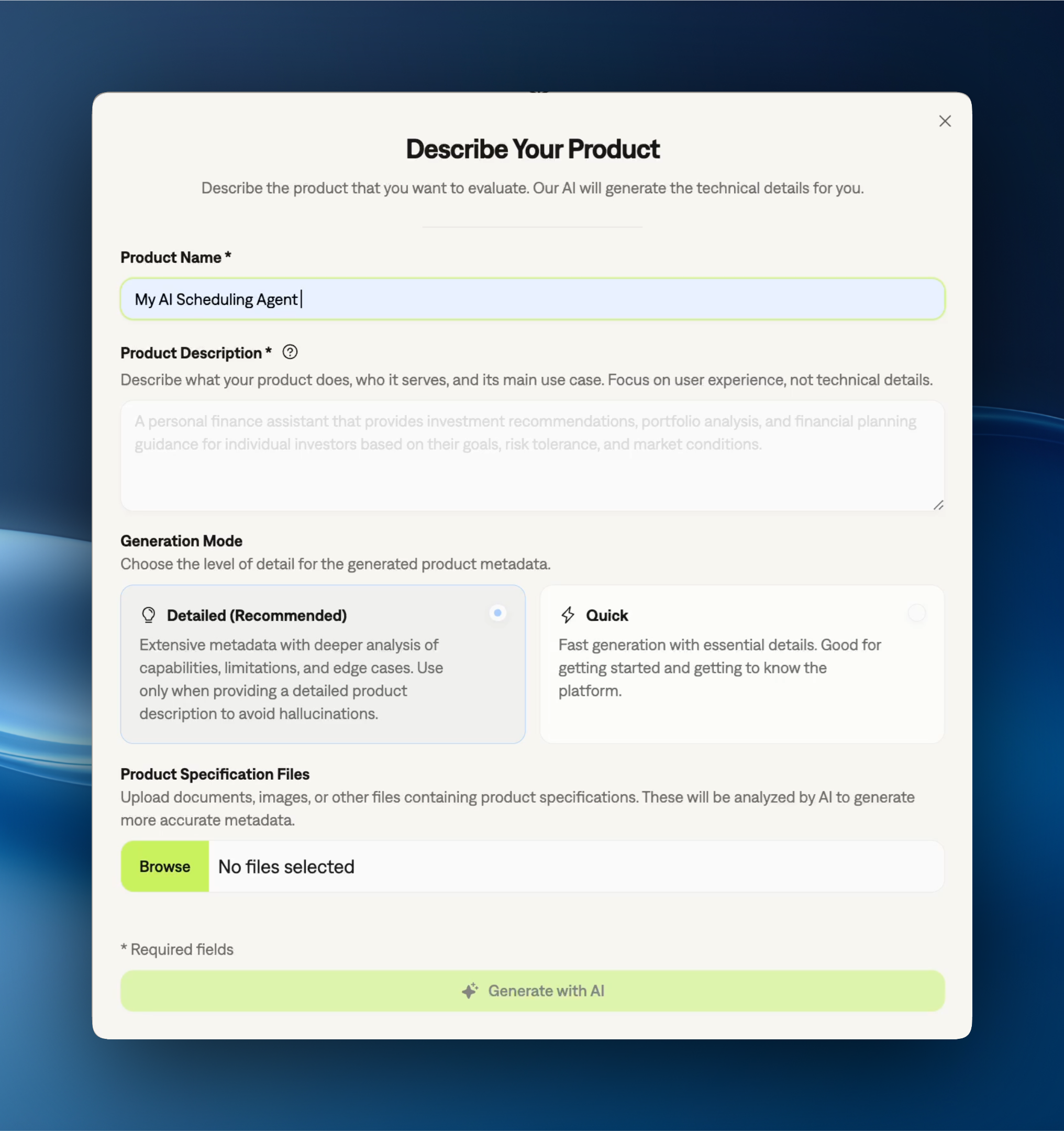
The product information is crucial – it powers our ability to generate synthetic test data that’s specific to your use case.
2. Get Started with the SDK
You can use Galtea from the dashboard or via the Python SDK. This quickstart uses the Python SDK.Get your API key
In the Galtea dashboard, copy the API key you created during your product page onboarding (or navigate to Settings > Generate API Key).
3. Version Your Product
Use versions to track iterations of your product and compare evaluation results over time. Each evaluation is tied to a version, so you can see how changes impact metrics. If you completed the Onboarding checklist on your product page, you already have an initial version (created automatically). To find IDs in the dashboard, open your product and click the 3-dot menu on any item, then select Copy ID. Alternatively, list them via the SDK:4. Create Your Tests
A single conversational product typically includes multiple components. In Galtea, you evaluate each component by creating a different test type, think of each test as a lens on the same system:- RAG pipelines → create an Accuracy test (
type="ACCURACY") - Security or safety aspects → create a Security & Safety test (
type="SECURITY") - Conversational scenarios → create a Behavior test (
type="BEHAVIOR")
After creating a test, give it a moment to finish generating test cases. You can track progress in the dashboard.
If you already created a test during onboarding, you can reuse it here—skip the
tests.create(...) step and just list its test cases using the test ID from the dashboard.- RAG
- Security
- Conversational
Accuracy tests are used to evaluate RAG pipelines and QA-style components within a conversational product. Galtea generates single-turn test cases (input and expected output) from a knowledge base to assess response quality and factual correctness.After a brief wait for test case generation, list the test cases:Learn more about Accuracy Tests and their configuration options.
5. Choose Your Metrics
Metrics define how evaluation outputs are scored. Galtea provides built-in metrics for common use cases (factual accuracy, faithfulness, toxicity, role adherence, and many more), and you can also create custom metrics with your own judge prompts. You can also generate metrics from specifications — the AI creates tailored judge prompts for each spec.- RAG
- Security
- Conversational
For a RAG-style Accuracy test, a good default is Factual Accuracy.
6. Run the Evaluation
Now connect Galtea to your product. You define an agent function — a wrapper that takes a test case input, calls your AI system, and returns its output. The SDK then loops through test cases, calls your agent, and scores the results via evaluations. The SDK supports three agent function signatures — pick the one that matches how much context your agent needs:- Simple
- Chat History
- Structured
The quickest way to get started. Your function receives just the latest user message as a string.
All three signatures work with
evaluations.run(), inference_results.generate(), and simulator.simulate(). Both sync and async functions are supported. The SDK auto-detects which signature you’re using from the type hint on the first parameter.For the full list of fields available on AgentInput (including structured input access via message metadata), see the AgentInput reference.- RAG
- Security
- Conversational
If you already computed a score, you can upload it directly:
{"name": "my-metric", "score": 0.85}.7. See Your Results
Once your evaluations are submitted, open your product in the Galtea platform and head to Analytics. Start with the aggregate scores to get a quick baseline, then slice by version, test, and metric to see where performance shifts. The most useful part is drilling into individual test cases: you can inspect the exact prompt/output pair (or the full conversation for scenarios) and understand which specific inputs move the score up or down. This makes it easier to identify failure patterns, validate fixes in new versions, and iterate with confidence as you move toward production.Next Steps
Congratulations! You’ve completed your first evaluation with Galtea. You can now explore more advanced features like:Tracing Agent Operations
Learn how to capture and analyze the internal operations of your AI agent.
Evaluating Production
Learn how to log and evaluate user queries from your production environment.
Specification-Driven Evaluations
Use specifications to automate test type selection and metric generation.
Dive Deeper
Explore these concepts to tailor tests, metrics, and workflows to your product. The Concepts overview shows how they all connect at a glance.Concepts overview
How Galtea’s concepts connect — diagram + per-entity quick reference.
Product
A functionality or service being evaluated
Version
A specific iteration of a product
Test
A set of test cases for evaluating product performance
Session
A full conversation between a user and an AI system.
Inference Result
A single turn in a conversation between a user and the AI.
Evaluation
The assessment of an evaluation using a specific metric’s criteria
Metric
Ways to evaluate and score product performance